20Case Study: Public Health and Epidemiological Data
20.1 Introduction: Integrating Exploration and Explanation in Public Health
Across the book, we developed a descriptive workflow that moves from type-aware summaries and associations to interactive exploration, interpretable machine learning, and communication-oriented visualization. This case study brings these pieces together in a public health setting.
The focus is intentionally practical. We work with a diabetes screening dataset and examine how interactive exploration and interpretable model summaries can support epidemiological understanding. We emphasize descriptive interpretation, transparent assumptions, and communication choices for mixed technical and non-technical audiences.
20.2 Public Health Context and Analytical Questions
We use the Pima diabetes data available in MASS (Pima.tr and Pima.te). The dataset includes physiological measurements and a binary diabetes outcome. While the sample is modest, it illustrates a common public health workflow where we combine exploratory visualization with interpretable probabilistic modeling.
We organize the analysis around four questions:
How does diabetes prevalence vary across key demographic and clinical strata?
How can an interactive Shiny interface support rapid epidemiological exploration?
What do partial dependence and Shapley-based summaries reveal about model behavior?
How can we communicate these findings clearly to non-technical stakeholders?
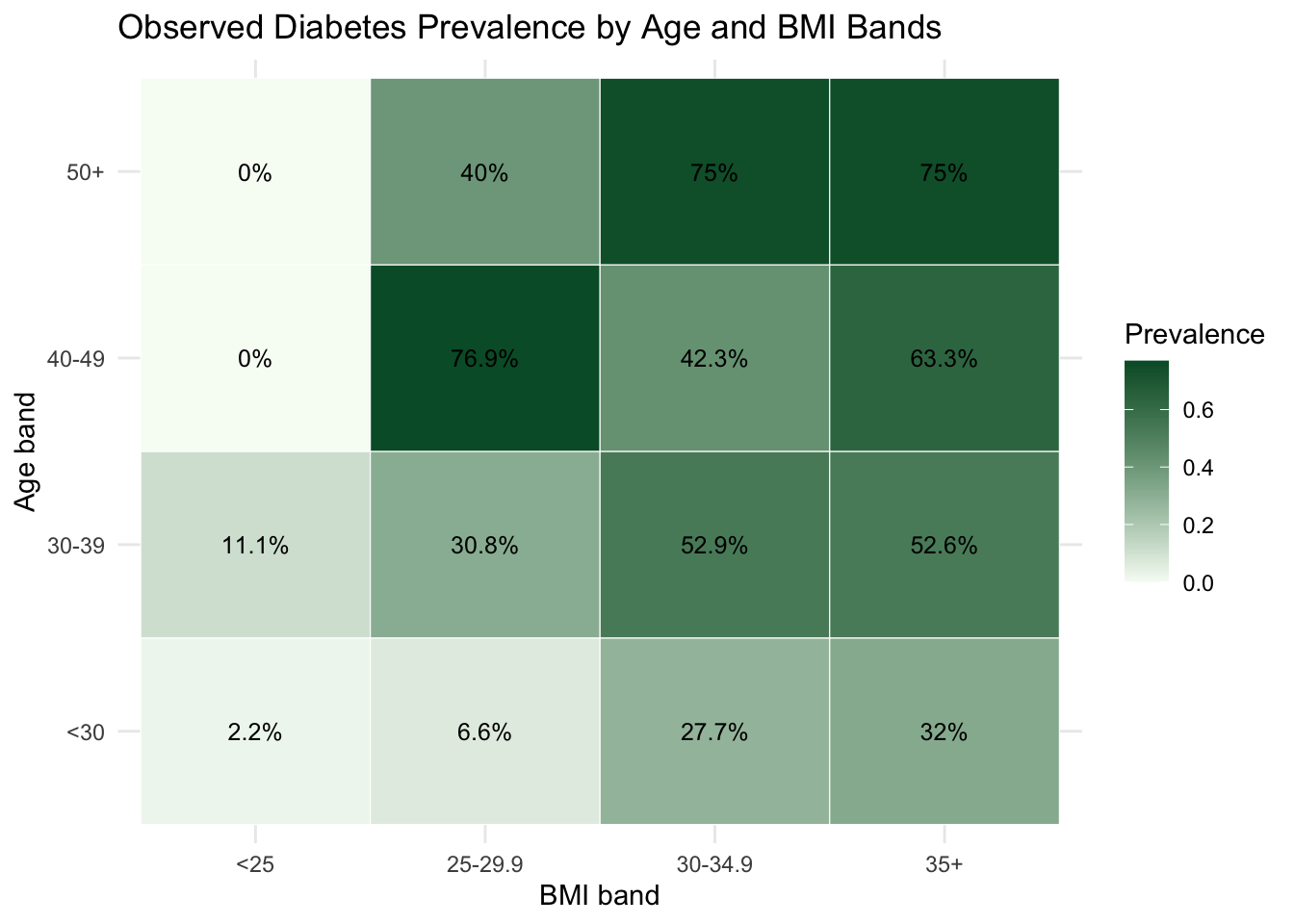
20.3 Data Assembly and Baseline Epidemiological Profile
We merge the training and test partitions into one analysis table, then create a binary indicator used in prevalence calculations.
This baseline view highlights heterogeneity that motivates the interactive and model-based steps that follow.
20.4 Interactive Exploration with a Shiny Workflow
As established in Chapter 7 and Chapter 8, interactive tools transform association analysis from a static snapshot into a dynamic conversation with data. Rather than each new question requiring code modification and recomputation, a Shiny interface allows filtering by subgroup, switching indicators, and adjusting parameters in real time. This iterative workflow is particularly valuable in public health settings, where the relevant question often shifts depending on which stratum or indicator the analyst focuses on.
The core Shiny architecture for a health indicator explorer follows the same reactive pattern developed in Chapter 7: a UI with controls for indicator selection and optional subgroup filtering, and a server that recomputes and re-renders plots reactively whenever an input changes.
library(shiny)# Minimal structure of the health indicator explorerui <-fluidPage(titlePanel("Public Health Indicator Explorer"),sidebarLayout(sidebarPanel(selectInput(inputId ="indicator",label ="Select indicator",choices =c("glu", "bp", "skin", "bmi", "ped", "age", "npreg"),selected ="glu" ),checkboxGroupInput(inputId ="diabetes_filter",label ="Diabetes status",choices =c("No", "Yes"),selected =c("No", "Yes") ) ),mainPanel(plotOutput("distribution_plot"),plotOutput("comparison_plot") ) ))server <-function(input, output) {# Reactive subset: updates whenever indicator or filter changes filtered_data <-reactive({ health_data |>filter(as.character(type) %in% input$diabetes_filter) }) output$distribution_plot <-renderPlot({filtered_data() |>ggplot(aes(x = .data[[input$indicator]], fill = type)) +geom_histogram(alpha =0.55, position ="identity", bins =25) +labs(x = input$indicator, y ="Count", fill ="Diabetes") +theme_minimal() }) output$comparison_plot <-renderPlot({filtered_data() |>ggplot(aes(x = type, y = .data[[input$indicator]], fill = type)) +geom_boxplot(alpha =0.7, width =0.55) +labs(x ="Diabetes status", y = input$indicator) +theme_minimal() +theme(legend.position ="none") })}
The reactive expression filtered_data() is the organizing principle: both plots depend on it, so changing either the indicator or the diabetes filter triggers a single re-evaluation of the subset and automatic re-rendering of all downstream outputs. This is the same reactive dependency graph pattern introduced in Chapter 7.
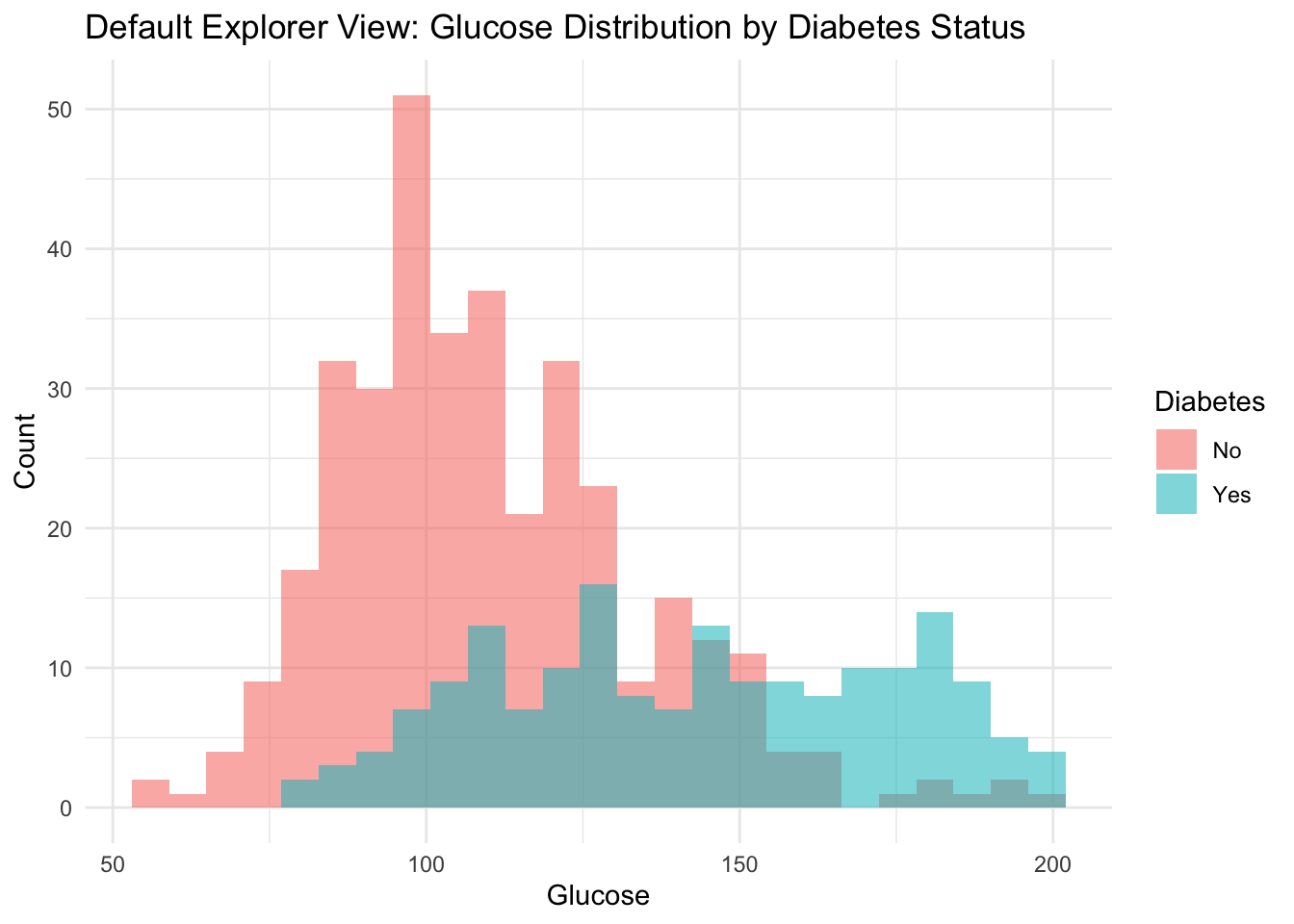
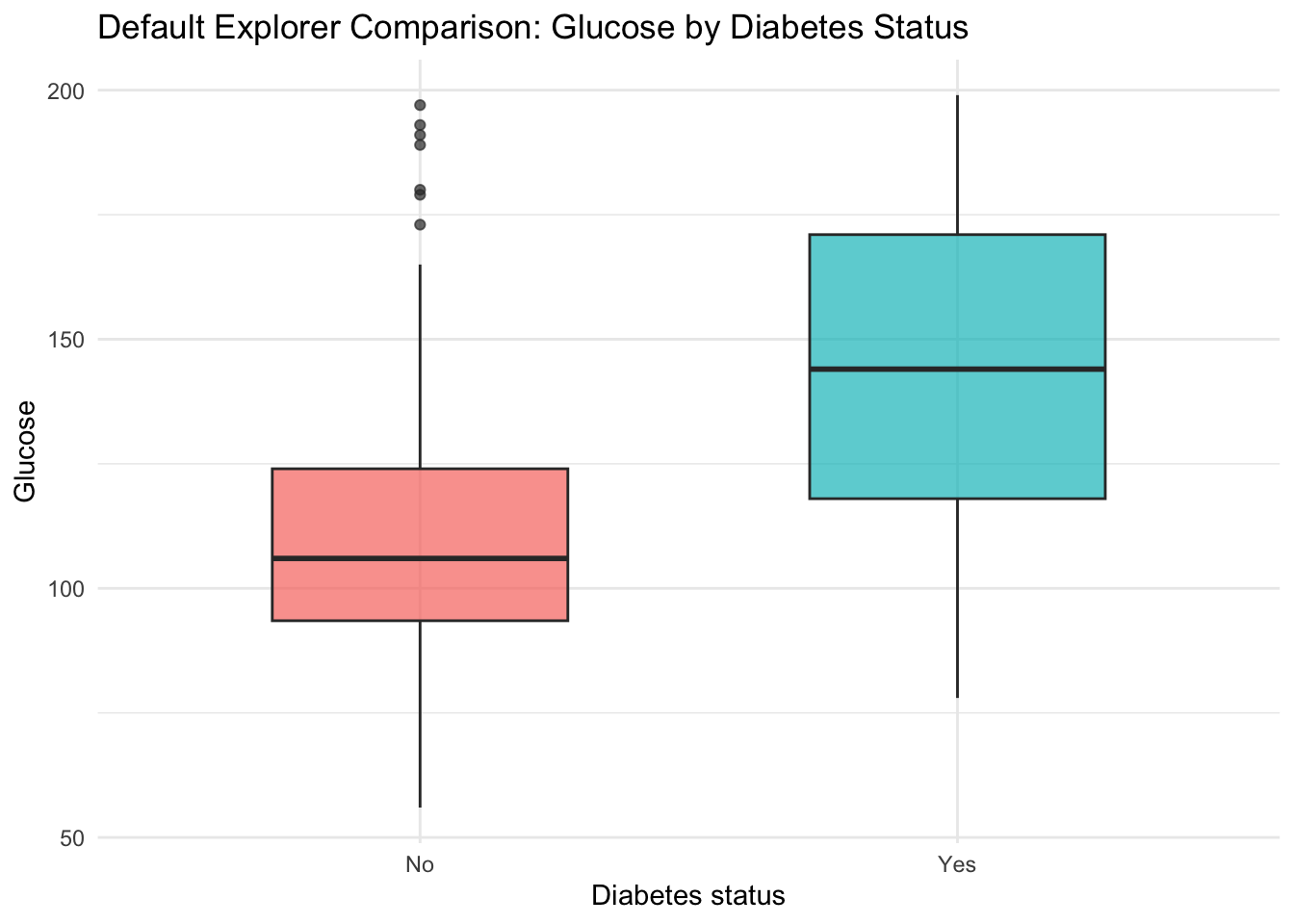
We now show a static default view equivalent to one state of the live app, then embed the deployed application.
default_indicator <-"glu"health_data |>ggplot(aes(x = .data[[default_indicator]], fill = type)) +geom_histogram(alpha =0.55, position ="identity", bins =25) +labs(title ="Default Explorer View: Glucose Distribution by Diabetes Status",x ="Glucose",y ="Count",fill ="Diabetes" ) +theme_minimal()
health_data |>ggplot(aes(x = type, y = glu, fill = type)) +geom_boxplot(alpha =0.7, width =0.55) +labs(title ="Default Explorer Comparison: Glucose by Diabetes Status",x ="Diabetes status",y ="Glucose",fill ="Diabetes" ) +theme_minimal() +theme(legend.position ="none")
The full source code of the application is available on GitHub.
This app-level workflow is useful when we want rapid subgroup checks before committing to a fixed modeling specification. The interactive layer also supports communication with non-technical stakeholders, who can explore the data themselves without reading code, aligning with the communication principles developed in Chapter 9.
20.5 Interpretable Model for Descriptive Risk Mapping
We now fit a random forest classifier to obtain smooth probability estimates and then interpret those estimates with partial dependence and Shapley-based summaries. The objective is descriptive mapping of model behavior, not predictive competition.
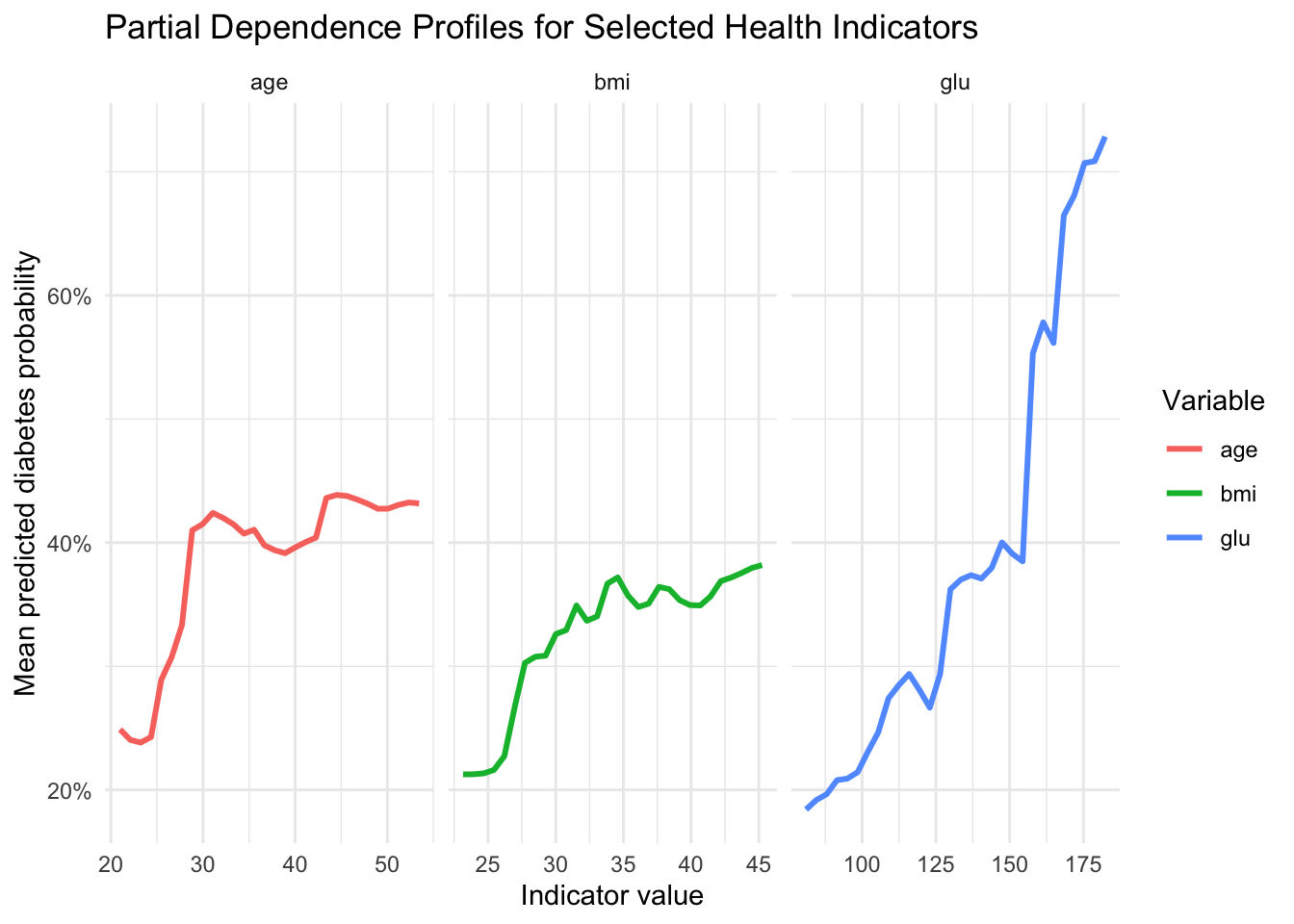
To study global model behavior, we compute partial dependence curves for glucose, BMI, and age. These are average model responses over a grid of values while integrating over the empirical distribution of other features.
pd_summary_tbl <- pd_tbl |>group_by(variable) |>summarise(pd_low =first(mean_pred_prob),pd_high =last(mean_pred_prob),pd_change = pd_high - pd_low,.groups ="drop" ) |>arrange(desc(pd_change))pd_summary_tbl |>gt() |>cols_label(variable ="Variable",pd_low ="Predicted probability at low grid value",pd_high ="Predicted probability at high grid value",pd_change ="Change" ) |>fmt_percent(columns =c(pd_low, pd_high, pd_change), decimals =1)
Variable
Predicted probability at low grid value
Predicted probability at high grid value
Change
glu
18.4%
72.8%
54.4%
age
24.9%
43.2%
18.3%
bmi
21.3%
38.2%
16.9%
In a public health framing, these profiles are useful for communicating directional gradients without reducing interpretation to a single coefficient.
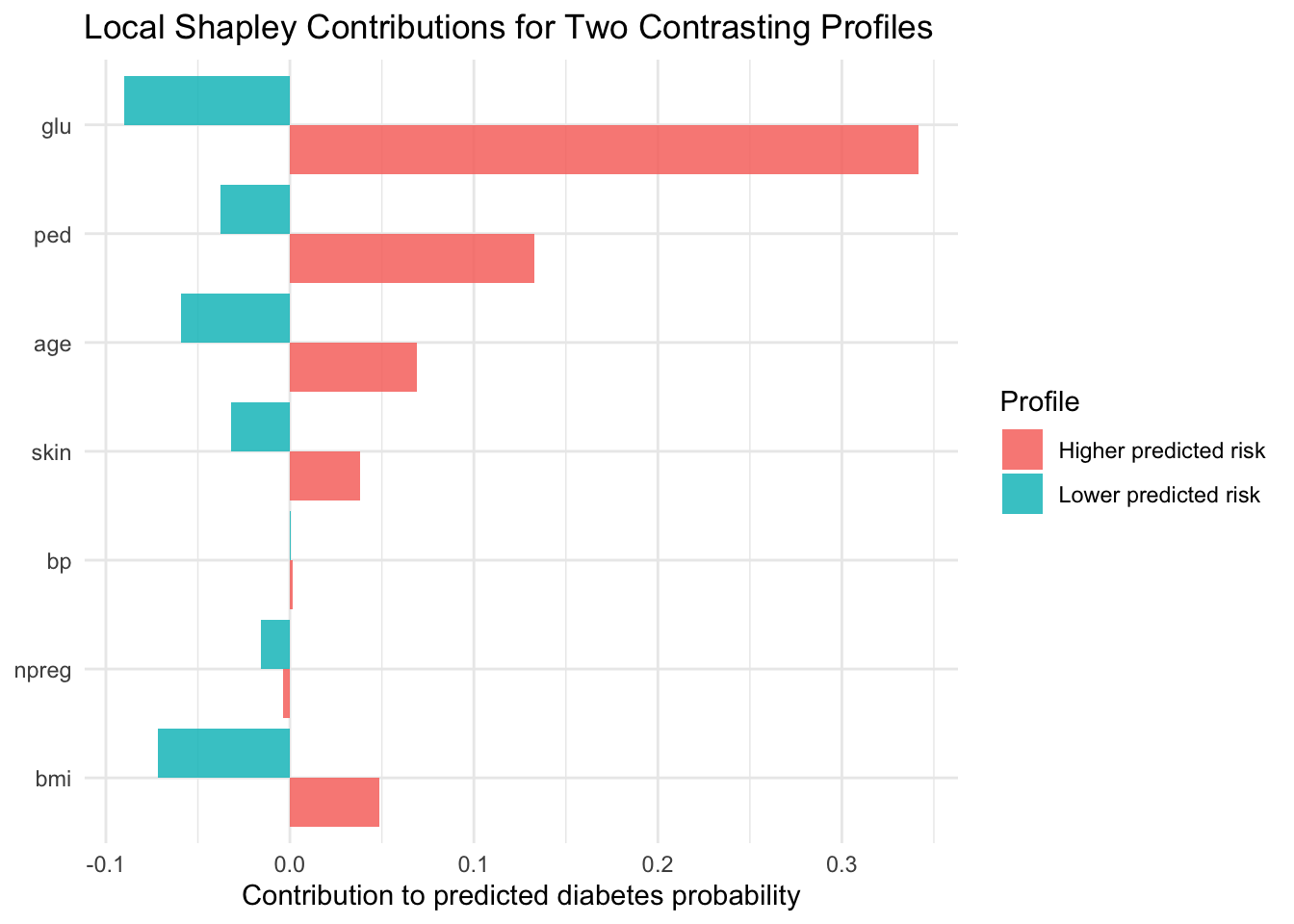
20.7 Local and Global Shapley-Based Explanations
Partial dependence provides global structure. We complement it with local additive decomposition, following the logic introduced in the chapter on Shapley values (Chapter 16).
Second, we summarize the analytical narrative in a message-evidence format that can be reused in technical briefs or public health dashboards.
Message 1. Higher glucose values are associated with higher model-estimated diabetes probability. The supporting evidence is that the partial dependence profile for glucose shows the largest increase from low to high values.
Message 2. BMI and age contribute to substantial between-profile risk heterogeneity. The supporting evidence is that Shapley summaries indicate meaningful local and global contributions from BMI and age.
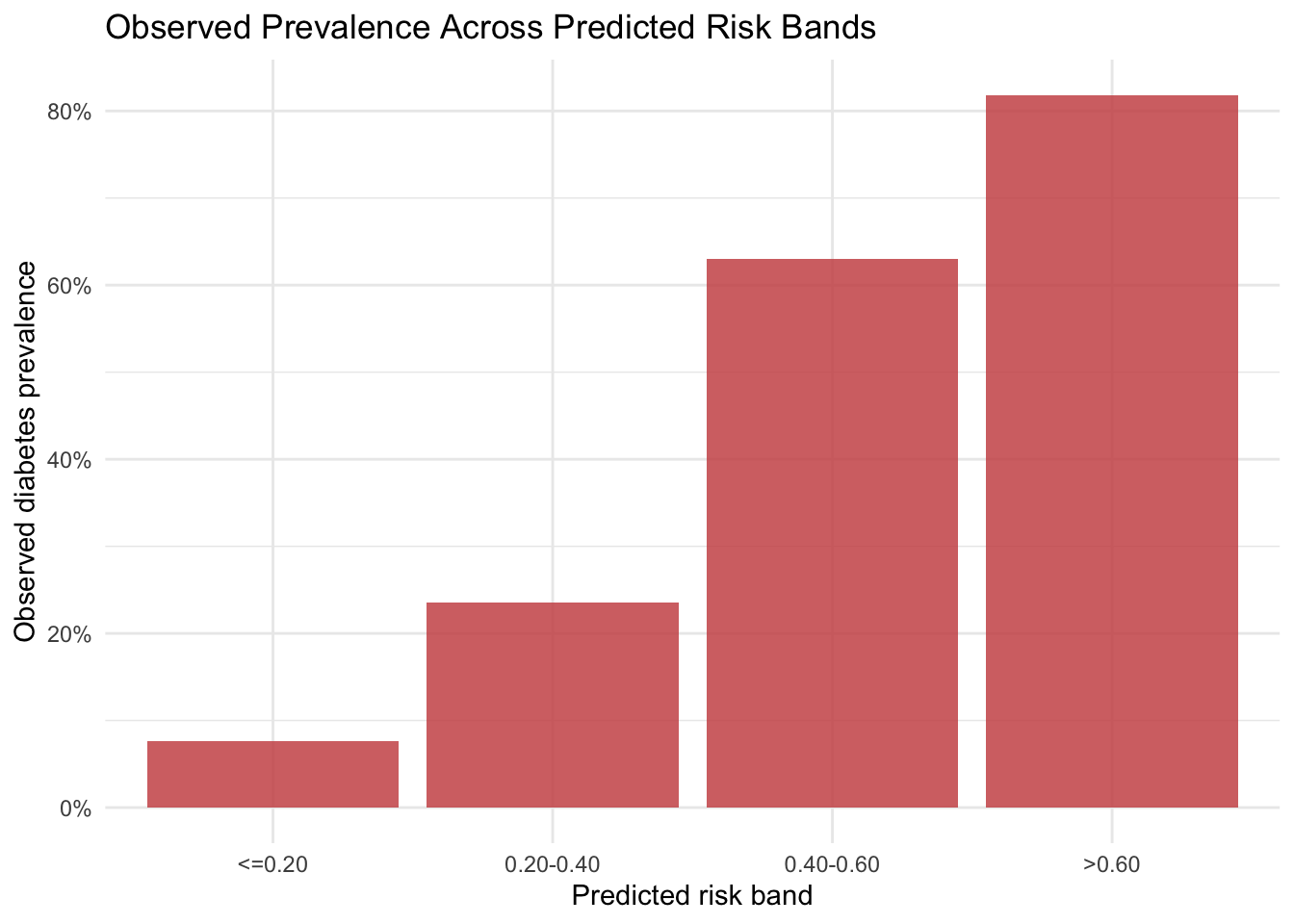
Message 3. Predicted risk strata correspond to increasing observed prevalence in holdout data. The supportifng evidence is that observed prevalence increases across ordered predicted-probability bands.
20.9 Limitations and Reproducibility Notes
Three considerations remain central.
The analysis is observational and descriptive, so interpretation should avoid causal claims.
The sample is specific and relatively compact, which limits transportability.
Shapley approximations are Monte Carlo estimates, so small contributions can vary with sampling settings.
All random components use explicit seeds. In practice, it is often useful to check sensitivity across additional resamples and alternative model classes.
20.10 Summary and Key Takeaways
Interactive Shiny exploration helps identify stable subgroup patterns before model fitting.
Partial dependence provides a clear global view of predictor-response gradients.
Shapley-based decomposition complements global profiles with case-level interpretation.
Risk-band summaries and message-evidence tables support communication with non-technical audiences.
The full workflow remains descriptive and should be communicated with corresponding caution.
20.11 Looking Ahead
This chapter centered on interactive exploration and interpretable machine learning in a public health context. The next case study shifts to business analytics, where AutoML and automated feature engineering will be used as descriptive instruments for customer insight generation.